PSA: FF3-1 Is No Longer Approved by NIST
Table of contents
- Public Service Announcement: FF3-1 is No Longer Secure
- What is FF3/FF3-1
- What is Format-Preserving Encryption?
- Why was FF3/FF3-1 removed by NIST?
- But wait, this is just a draft! Shouldn't we wait for the final revision?
- What does this mean for the future of Format-Preserving Encryption?
- Did you invent FF3/FF3-1?
- Will you write an implementation of FF1?
- How did you find about this?
- How was Project Hail Mary?
Public Service Announcement: FF3-1 is No Longer Secure
FF3-1, a mode of Format-Perserving Encryption and the topic of my capstone project has been removed as an approved cryptographic mode of operation in NIST SP 800-38G Rev. 1 (2nd Public Draft). This signifies that attacks against FF3-1 have advanced to the point where it no longer provides strong cryptographic protection.
What follows are frequently asked questions about this change, or a list of questions I think people would ask if they frequently asked questions.
What is FF3/FF3-1
FF3-1 (Format-preserving, Feistel-based, 3rd submission, 1st revision) is a format-preserving encryption scheme, based on a modified version of the BPS-BC cipher designed by Brier, Peyrin, and Stern. It was submitted to NIST for inclusion in its Recommendation for Block Cipher Modes of Operation: Methods for Format-Preserving Encryption as FF3.
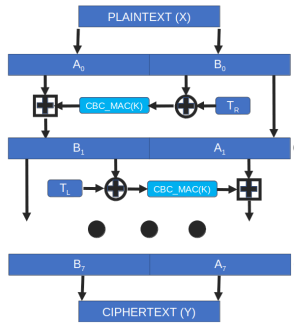
FF3 is a Feistel structure - it uses a round function, in this case CBC-MAC, and a tweak value. The tweak is designed to protect against dictionary attacks - very similar to the way a salt value protects a hash output for password protection. Each round takes in one half of the plaintext, XORs it with the tweak, passes into the CBC-MAC function, and then uses modular addition (that funky square plus symbol) to combine the results with the other half of the plaintext. The process alternates, running a total of eight times, and the output is the final encrypted ciphertext.
It's the use of the tweak that would lead to the attacks that broke FF3 (and later FF3-1). While the tweak is used as a parameter to the encryption function, it does not have any cryptographic properties. It's not required to be random, and indeed a tweak is not even required at all! Basically, when an attacker can choose the tweak values, and receive a significant number of ciphertexts encrypted under related tweaks, it can lead to message recovery in a relatively small number of operations, especially over small domains. Additionally, Durak and Vaudenay effectively lowered the eight rounds in the FF3 Feistel construction to four rounds using a "slide attack" on the tweak function, constituting a complete break of the FF3 algorithm.
Due to attacks on the tweak schedule the original algorithm was modified as FF3-1 with changes to the construction of the tweak. Now, due to improved attacks by Beyne on the modified tweak that leads to message recovery, the algorithm has been withdrawn completely.
What is Format-Preserving Encryption?
Format-Preserving Encryption (FPE) is a form of encryption that maintains the format of the original item that is being encrypted. It's pretty cool stuff; if you encrypt a Social Security Number, which is a 9 digit number, the ciphertext will also be a 9 digit number. The ciphertext is also the same format (let me get them digits!) and the same length of the plaintext.
Here's a fake social security number "123456789" encrypted under FF3-11. Note the ciphertext is also a nine digit number.
from FF3 import FF3
from Crypto.Random import get_random_bytes
alphabet = "0123456789"
radix = len(alphabet)
key = get_random_bytes(16)
fpe = FF3(radix, alphabet, key)
tweak = get_random_bytes(7)
pt = "123456789"
ct = fpe.encrypt(pt, tweak)
Plaintext: 123456789
Ciphertext: 542308893
Compare that to the encryption of the same fake social security number in AES-GCM mode. For comparison sake, we'll show the original "123456789" in hexadecimal format.2
data = b"123456789"
key = get_random_bytes(16)
cipher = AES.new(key, AES.MODE_GCM)
ciphertext, tag = cipher.encrypt_and_digest(data)
Plaintext as hex: 313233343536373839
Ciphertext: acf67f543760da0552
Tag: 810ecafe6cb22867381bbcc0413be31b
Nonce: be7b92a4b8ae556d6d933b283386d802
AES-GCM is actually pretty neat. It will produce a ciphertext that is the same size as the input of the plaintext. However, the algorithm still needs a 96-bit nonce (number used once) and outputs a 128-bit authentication tag. The result is objectively more secure3 than any format-preserving encryption scheme - it provides zero knowledge of the plaintext other than the length, and provides integrity protection via the tag element. The downside is now you have to store the ciphertext, the nonce, and the tag.
Format-preserving encryption is nice for legacy databases and applications - it may be infeasible to modify these apps to support modern encryption schemes like AES-GCM, but you could still retrofit strong cryptography and protect sensitive personal and financial data.
The removal of FF3 (for sound reasoning) unfortunately removes an arrow from that quiver.
Why was FF3/FF3-1 removed by NIST?
The original published NIST 800-38G specified two modes of operation, FF1, which was based on FFX, and FF3, based on BPS4. There was another mode, FF2, which was removed from final consideration.
The first attacks on the published format-preserving encryption schemes targeted small domains of four bytes or less (think using FPE to encrypt a U.S. State Letter code or very short last names like "Lee"). In these scenarios, message recovery5 can be accomplished with 232 operations. NIST targets at least 2112 operations before strong encryption schemes are broken. That's no good.
Additionally, FF3 was found to have bad domain separation in the implementation of the tweak, leading to a complete break of FF3.
In 2019, NIST issued NIST 800-38G Rev. 1 which required domain sizes of one million and introduced FF3-1, a modified version of FF3 designed to fix the bad domain separation caused by the tweak parameter.
Attacks continued to improve. In 2021, Beyne showed attacks on the FF3-1 algorithm, on the new domain sizes of one million, that allowed partial message recovery in 224 queries, using linear cryptanalysis6.
Based on the analysis and practicality of the the Beyne attacks, NIST decided to remove FF3-1 in the second public draft of NIST 800-38G Rev. 1 - 2PD.
But wait, this is just a draft! Shouldn't we wait for the final revision?
Technically, the revision that introduced FF3-1 was also just a draft. That doesn't make the attacks on FF3-1 any less real.
Technology moves fast, and there's a pretty good chance that when you connected to this page over Transport Layer Security you used Hybrid Key Exchange in TLS 1.37, which is also just a draft. Yet, hybrid key exchange is already being used to encrypt a majority of traffic to CloudFlare's Lava Lamps.

What does this mean for the future of Format-Preserving Encryption?
FF1 is still an approved mode of operation based on current cryptanalysis, provided that the specification is followed:
The parameters radix, minlen, and maxlen in FF1.Encrypt and FF1.Decrypt
shall meet the following requirements:
• radix ∈ [2..216]
• radixminlen ≥ 1000000
• 2 ≤ minlen ≤ maxlen < 232
Did you invent FF3/FF3-1?
Goodness, no! For my capstone project to complete my Online Master of Science in Cybersecurity, I wrote an implementation of FF3-1 in Python. The goal was to integrate it with PyCryptodome, including test vectors from NIST ACVP and documentation. My paper also reviewed the security goals of FPE and summarized the threat model.
I wanted to release the implementation under the BSD-2 license, so I wrote the implementation only from the specification in NIST and the original BPS-BC paper. It's not exactly a clean room to clone an IBM machine, but considering you can't even use a search engine in 2026 without an AI overview I'm still proud of my effort.
Will you write an implementation of FF1?
The FF1/FFX algorithm is patented by Voltage Systems which requires license costs for implementations. In short, no.
How did you find about this?
Funny story, I woke up this morning to a comment on the pull request I submitted to PyCryptodome stating that FF3-1 would be removed from NIST for being too insecure, thus the pull request was closed. That request had been stale for about four years and I never expected anything to come of it.
In my groggy state, I thought the second public draft was released in February of 2026. Turns out, its been around since February of 2025, so I was only off by thirteen months.
How was Project Hail Mary?
Excellent. I laughed. I cried. I really can't say anything else without giving away spoilers, but I highly recommend you give them your money.
-
This is an independent version of the implementation submitted as a pull request to PyCryptodome. It's only dependency is the AES ECB mode of operation. It's not published, thus the code here is for reference. ↩
-
Remember that everything in computer world is a bit, 0 or 1. A string is just a representation of printable characters, UTF-8 being the most prevalent encoding option which is backwards compatible with ASCII. Hexadecimal is a number system in Base 16 and is particualrly suited for representing bytes, two hexadecimal digits can display one byte. ↩
-
AES-GCM is considered IND-CCA2 (Indistinguishable under Adaptive Ciphertext Attack) - the best any format-preserving encryption scheme can hope for, because the scheme is deterministic, is Strong PRP security. ↩
-
The link here is the attestation by the authors that they didn't hold any patents on BPS. There was an associated academic paper titled "BPS: a Format-Preserving Encryption Proposal" originally hosted by Penn State that now redirects to the Way Back Machine. It's effectively disappeared from the Internet. ↩
-
Message recovery is exactly how it sounds, the attacker can recover all or part of the original plaintext. When the goal is confidentiality, this is obviously very bad - even partial recovery of a plaintext can be catastrophic. ↩
-
Understanding linear cryptanalysis is left as an exercise to the reader. ↩
-
Hybrid key exchange leverages a classical algorithm like X25519 elliptic curve with a post-quantum safe ML-KEM key exchange. As long as one of the schemes is secure, the underlying session key cannot be recovered. This is useful since some early post quantum schemes were somewhat less secure than hoped ↩